Kevin Klues
A Deep Dive on How To Leverage the NVIDIA GB200 for Ultra-Fast Training and Inference on Kubernetes
#1about 2 minutes
Understanding the NVIDIA GB200 supercomputer architecture
The GB200 uses multi-node NVLink and NV switches to connect up to 72 GPUs across multiple nodes, creating a single powerful system.
#2about 2 minutes
Enabling secure multi-node GPU communication on Kubernetes
While the GPU Operator runs on GB200 nodes, it requires support for a new construct called IMEX to securely leverage multi-node NVLink connections.
#3about 2 minutes
How the IMEX CUDA APIs enable remote memory access
Applications use a sequence of CUDA API calls like `cuMemCreate` and `cuMemExportToShareHandle` to securely map and access remote GPU memory over NVLink.
#4about 4 minutes
Exploring the four levels of IMEX resource partitioning
IMEX security is managed through a four-level hierarchy, from the physical NVLink Domain down to the workload-specific IMEX Channel allocated within an IMEX Domain.
#5about 6 minutes
Abstracting IMEX complexity with the compute domain concept
The complex manual setup of IMEX daemons and channels is hidden behind a user-friendly "Compute Domain" abstraction that uses Dynamic Resource Allocation (DRA).
#6about 2 minutes
How to migrate a multi-node workload to compute domains
Migrating a workload involves creating a `ComputeDomain` object and updating the pod spec to reference its `resourceClaimTemplate` in the new `resourceClaims` section.
#7about 5 minutes
Understanding the compute domain DRA driver's architecture
The driver uses a central controller and a Kubelet plugin to orchestrate the lifecycle of IMEX daemons and channels, ensuring they are ready before workloads start.
#8about 6 minutes
Demonstrating a multi-node MPI job on a GB200 cluster
A live demo shows how to deploy the DRA driver and run an MPI job that automatically gets IMEX daemons and achieves full NVLink bandwidth across nodes.
#9about 2 minutes
Prerequisites and resources for using the DRA driver
To use the driver, you must enable DRA and CDI feature flags in Kubernetes and ensure the GPU driver includes the necessary IMEX binaries.
Related jobs
Jobs that call for the skills explored in this talk.
Wilken GmbH
Ulm, Germany
Senior
Amazon Web Services (AWS)
Kubernetes
+1
Matching moments

02:52 MIN
Key hardware and network design for AI infrastructure
Your Next AI Needs 10,000 GPUs. Now What?
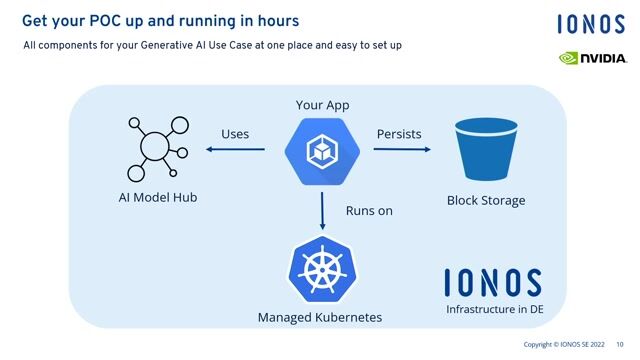
02:38 MIN
Enabling direct GPU access within managed Kubernetes
From foundation model to hosted AI solution in minutes
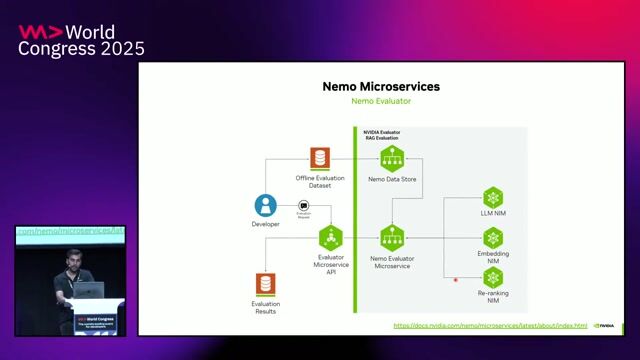
03:08 MIN
Deploying and scaling models with NVIDIA NIM on Kubernetes
LLMOps-driven fine-tuning, evaluation, and inference with NVIDIA NIM & NeMo Microservices

02:27 MIN
A look inside the NIM container architecture
Efficient deployment and inference of GPU-accelerated LLMs
01:57 MIN
Highlighting impactful contributions and the rise of open models
Open Source: The Engine of Innovation in the Digital Age

03:18 MIN
Accessing global GPU capacity with DGX Cloud Lepton
Your Next AI Needs 10,000 GPUs. Now What?
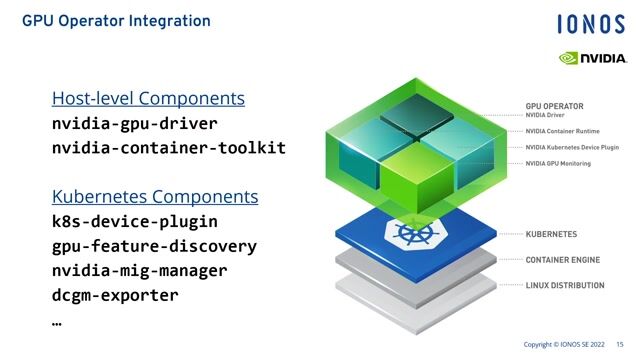
03:08 MIN
Deploying custom inference workloads with NVIDIA NIMs
From foundation model to hosted AI solution in minutes

01:46 MIN
Accessing software, models, and training resources
Accelerating Python on GPUs
Featured Partners
Related Videos
 29:52
29:52Your Next AI Needs 10,000 GPUs. Now What?
Anshul Jindal & Martin Piercy
 22:07
22:07WWC24 - Ankit Patel - Unlocking the Future Breakthrough Application Performance and Capabilities with NVIDIA
Ankit Patel
 18:33
18:33From foundation model to hosted AI solution in minutes
Kevin Klues
 24:39
24:39Accelerating Python on GPUs
Paul Graham
 23:01
23:01Efficient deployment and inference of GPU-accelerated LLMs
Adolf Hohl
 22:18
22:18Accelerating Python on GPUs
Paul Graham
 30:46
30:46The Future of Computing: AI Technologies in the Exascale Era
Stephan Gillich, Tomislav Tipurić, Christian Wiebus & Alan Southall
 24:26
24:26AI Factories at Scale
Thomas Schmidt
Related Articles
View all articles



From learning to earning
Jobs that call for the skills explored in this talk.

ITproposal B.V.
Eindhoven, Netherlands
Senior
Bash
Azure
DevOps
Python
Ansible
+8
Avantgarde Experts GmbH
München, Germany
Junior
C++
GIT
CMake
Linux
DevOps
+3
Nvidia
München, Germany
€230K
Senior
API
Terraform
Kubernetes
Amazon Web Services (AWS)
Nvidia
Bramley, United Kingdom
£230K
Senior
API
Terraform
Kubernetes
Amazon Web Services (AWS)
Nvidia
Central Milton Keynes, United Kingdom
£221K
Senior
C++
Python
Docker
Ansible
+4
NVIDIA
Zwolle, Netherlands
Senior
Linux
DevOps
Python
OpenCL
Docker