Chris Heilmann, Daniel Cranney, Raphael De Lio & Developer Advocate at Redis
WeAreDevelopers LIVE - Vector Similarity Search Patterns for Efficiency and more
#1about 8 minutes
Getting hired through open source and passion projects
Hear how contributing to open source and sharing your work publicly can lead directly to job opportunities in developer advocacy.
#2about 5 minutes
How critical analysis can accelerate your career
Discover how publicly analyzing and improving upon existing technologies can make you a highly visible and attractive candidate for top companies.
#3about 3 minutes
The hidden costs of large LLM context windows
Understand why simply using larger context windows in models like GPT-5 is not a scalable or cost-effective solution for production applications.
#4about 3 minutes
A quick primer on vectors and vector search
A brief explanation of how text is converted into numerical vectors to represent its semantic meaning, enabling similarity searches.
#5about 9 minutes
Using semantic classification to categorize text
Learn how to use a vector database with reference examples to classify text, avoiding costly LLM calls for simple categorization tasks.
#6about 5 minutes
Implementing semantic routing for tool calling and guardrails
Discover how to use semantic routing to direct user prompts to the correct function or to block inappropriate topics without involving an LLM.
#7about 6 minutes
Reducing latency and cost with semantic caching
Implement semantic caching to store and retrieve answers for semantically similar user questions, drastically reducing redundant LLM calls and improving response time.
#8about 6 minutes
Optimizing accuracy for classification and tool calling
Explore techniques like self-improvement, hybrid fallbacks, and prompt chunking to fine-tune and improve the accuracy of your semantic patterns.
#9about 4 minutes
Advanced caching with specialized embedding models
Learn how to avoid common caching pitfalls, such as misinterpreting negation, by using specialized embedding models trained for semantic caching.
#10about 16 minutes
Q&A on data freshness, persistence, and management
The discussion covers practical considerations like preventing stale cache data with TTL, managing data ownership, and how Redis handles persistence.
Related jobs
Jobs that call for the skills explored in this talk.
Wilken GmbH
Ulm, Germany
Senior
Amazon Web Services (AWS)
Kubernetes
+1
VECTOR Informatik
Stuttgart, Germany
Senior
Java
IT Security
Matching moments
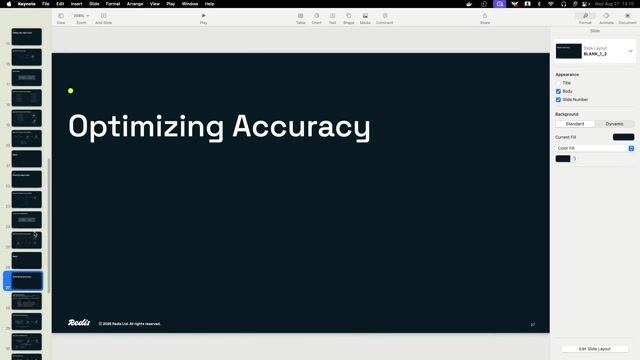
06:47 MIN
Strategies for optimizing vector search accuracy
Reducing LLM Calls with Vector Search Patterns - Raphael De Lio (Redis)

05:25 MIN
Reducing latency and cost with semantic caching
Reducing LLM Calls with Vector Search Patterns - Raphael De Lio (Redis)

04:30 MIN
Advanced patterns for building sophisticated AI applications
Java Meets AI: Empowering Spring Developers to Build Intelligent Apps
01:48 MIN
Solving LLM limitations with RAG and vector databases
Accelerating GenAI Development: Harnessing Astra DB Vector Store and Langflow for LLM-Powered Apps

03:21 MIN
Using caching to serve pre-generated AI responses
Performant Architecture for a Fast Gen AI User Experience

06:44 MIN
Exploring recent AI incidents and creative developer hacks
WeAreDevelopers LIVE - SpeculAItions

05:19 MIN
Vector search as the memory layer for RAG and Agentic AI
How to Decipher User Uncertainty with GenAI and Vector Search

00:56 MIN
Strategies for integrating local LLMs with your data
Self-Hosted LLMs: From Zero to Inference
Featured Partners
Related Videos
 34:39
34:39Reducing LLM Calls with Vector Search Patterns - Raphael De Lio (Redis)
 1:00:56
1:00:56Enter the Brave New World of GenAI with Vector Search
Mary Grygleski
 58:00
58:00Creating Industry ready solutions with LLM Models
Vijay Krishan Gupta & Gauravdeep Singh Lotey
 32:26
32:26Bringing the power of AI to your application.
Krzysztof Cieślak
 53:46
53:46WeAreDevelopers LIVE – AI vs the Web & AI in Browsers
Chris Heilmann, Daniel Cranney & Raymond Camden
 57:52
57:52Develop AI-powered Applications with OpenAI Embeddings and Azure Search
Rainer Stropek
 59:38
59:38What comes after ChatGPT? Vector Databases - the Simple and powerful future of ML?
Erik Bamberg
 28:57
28:57Accelerating GenAI Development: Harnessing Astra DB Vector Store and Langflow for LLM-Powered Apps
Dieter Flick & Michel de Ru
Related Articles
View all articles



From learning to earning
Jobs that call for the skills explored in this talk.


The Rolewe
Charing Cross, United Kingdom
API
Python
Machine Learning
Imec
Azure
Python
PyTorch
TensorFlow
Computer Vision
+1
LinkiT
Amsterdam, Netherlands
Azure
DevOps
Python
PySpark
Terraform
+2
WeCloudData
Remote
Python
Machine Learning
Continuous Integration