Ayon Roy
PySpark - Combining Machine Learning & Big Data
#1about 3 minutes
Combining big data and machine learning for business insights
The exponential growth of data necessitates combining big data processing with machine learning to personalize user experiences and drive revenue.
#2about 3 minutes
An introduction to the Apache Spark analytics engine
Apache Spark is a unified analytics engine for large-scale data processing that provides high-level APIs and specialized libraries like Spark SQL and MLlib.
#3about 4 minutes
Understanding Spark's core data APIs and abstractions
Spark's data abstractions evolved from the low-level Resilient Distributed Dataset (RDD) to the more optimized and user-friendly DataFrame and Dataset APIs.
#4about 11 minutes
How the Spark cluster architecture enables parallel processing
Spark's architecture uses a driver program to coordinate tasks across a cluster manager and multiple worker nodes, which run executors to process data in parallel.
#5about 5 minutes
Using Python with Spark through the PySpark library
PySpark provides a Python API for Spark, using the Py4J library to communicate between the Python process and Spark's core JVM environment.
#6about 5 minutes
Exploring the key features of the Spark MLlib library
Spark's MLlib offers a comprehensive toolkit for machine learning, including pre-built algorithms, featurization tools, pipelines for workflow management, and model persistence.
#7about 4 minutes
The standard workflow for machine learning in PySpark
A typical machine learning workflow in Spark involves using DataFrames, applying Transformers for feature engineering, training a model with an Estimator, and orchestrating these steps with a Pipeline.
#8about 3 minutes
Pre-built algorithms and utilities available in Spark MLlib
MLlib includes a variety of common, pre-built algorithms for classification, regression, and clustering, such as logistic regression, SVM, and K-means clustering.
Related jobs
Jobs that call for the skills explored in this talk.
Matching moments

01:29 MIN
Overview of the data and machine learning tech stack
Empowering Retail Through Applied Machine Learning

01:29 MIN
Q&A: Raw data formats and comparing dbt to Spark
Enjoying SQL data pipelines with dbt

05:53 MIN
Q&A on parallel computing, data versioning, and security
DevOps for Machine Learning
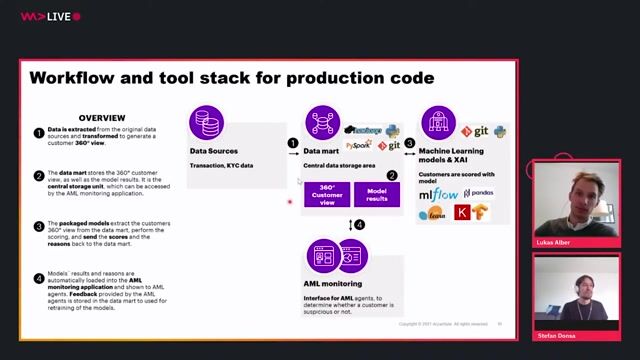
03:27 MIN
The production architecture and technology stack for AML AI
Detecting Money Laundering with AI

01:31 MIN
Key takeaways for modern data processing
Convert batch code into streaming with Python
01:57 MIN
Presenting live web scraping demos at a developer conference
Tech with Tim at WeAreDevelopers World Congress 2024

01:46 MIN
Going beyond standard aggregations in Spark
Let's Get Aggregated: Custom UDAFs in Spark

02:59 MIN
Comparing methods for machine learning with databases
Using WebAssembly for in-database Machine Learning
Featured Partners
Related Videos
 57:46
57:46Overview of Machine Learning in Python
Adrian Schmitt
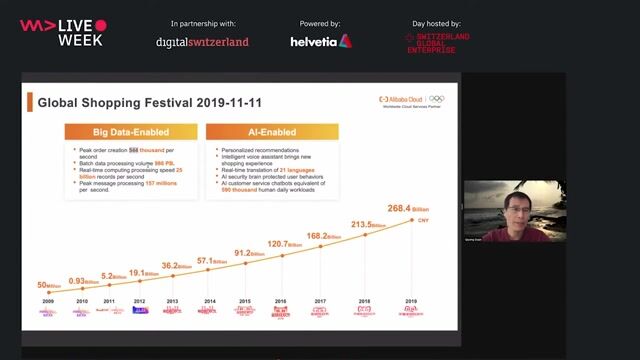 43:57
43:57Alibaba Big Data and Machine Learning Technology
Dr. Qiyang Duan
 39:04
39:04Python-Based Data Streaming Pipelines Within Minutes
Bobur Umurzokov
 39:14
39:14Fully Orchestrating Databricks from Airflow
Alan Mazankiewicz
 46:43
46:43Convert batch code into streaming with Python
Bobur Umurzokov
 29:37
29:37Detecting Money Laundering with AI
Stefan Donsa & Lukas Alber
 59:43
59:43Accelerating Python on GPUs
Paul Graham
 38:50
38:50Let's Get Started With Apache Kafka® for Python Developers
Lucia Cerchie
Related Articles
View all articles



From learning to earning
Jobs that call for the skills explored in this talk.

Client Server
Newcastle upon Tyne, United Kingdom
Remote
£90-120K
Hive
Spark
Python
+2
CAS
Municipality of Madrid, Spain
Intermediate
Spark
Python
Docker
PySpark
Microsoft Office
+1
ON Data Staffing
Senior
Spark
PyTorch
TensorFlow
Machine Learning
ITproposal B.V.
Amsterdam, Netherlands
Senior
Azure
Python
PySpark
Agile Methodologies