Artem Volk & Fabian Zillgens
Building the platform for providing ML predictions based on real-time player activity
#1about 3 minutes
Customizing the player experience in real time
The business goal is to use real-time player activity to deliver personalized in-game content, such as customized store offers.
#2about 3 minutes
Designing the high-level system architecture
The platform follows a three-stage architecture for event collection, data processing, and customization delivery using a standard AWS tech stack.
#3about 2 minutes
Building a resilient event collection pipeline
A slim API endpoint ingests high-volume, potentially out-of-order player events and uses an Amazon Kinesis stream to decouple it from downstream processing.
#4about 2 minutes
Separating offline and online data processing
The system uses a dual-path approach, with Apache Spark for offline analytics and Apache Flink with Flink SQL for real-time feature extraction.
#5about 2 minutes
Creating a low-latency user profile service
A user profile API stores a real-time snapshot of the player's state, updated by the Flink stream with a latency of around 200 milliseconds.
#6about 3 minutes
Delivering customizations via decoupled ML models
Machine learning models are deployed as independent AWS Lambda functions that data scientists can manage, allowing the game to pull personalized content on demand.
#7about 5 minutes
Analyzing system latency and architectural trade-offs
Empowering data scientists with monitoring tools reveals end-to-end latency metrics and highlights the advantages and costs of a highly decoupled system.
#8about 2 minutes
Implementing AWS cost optimization strategies
Costs are managed through techniques like event batching, data compression, aggressive Kinesis autoscaling, and S3 data partitioning and storage classes.
#9about 7 minutes
Q&A on model quality, scale, and player privacy
The team answers audience questions about event volume, ensuring model quality, load balancing, using AWS ML services, and handling player data privacy.
Related jobs
Jobs that call for the skills explored in this talk.
Wilken GmbH
Ulm, Germany
Senior
Amazon Web Services (AWS)
Kubernetes
+1
Bonial International GmbH
Berlin, Germany
Senior
Python
Java
+1
Matching moments

03:05 MIN
Building a real-time inference architecture on AWS
The Road to MLOps: How Verivox Transitioned to AWS
03:18 MIN
Exploring the platform's technology stack and architecture
Shared mobility for everyone!

04:50 MIN
Q&A on gamification, scaling, and the future of DevOps
We adopted DevOps and are Cloud-native, Now What?
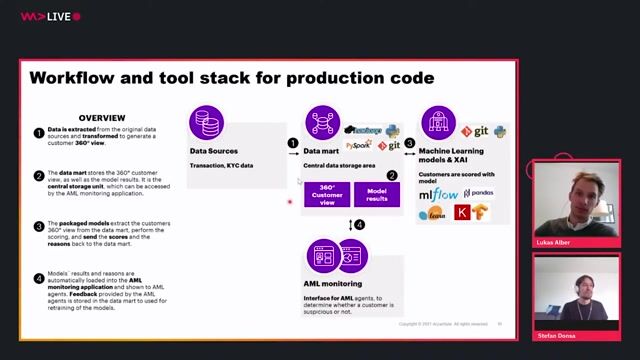
03:27 MIN
The production architecture and technology stack for AML AI
Detecting Money Laundering with AI

01:29 MIN
Overview of the data and machine learning tech stack
Empowering Retail Through Applied Machine Learning
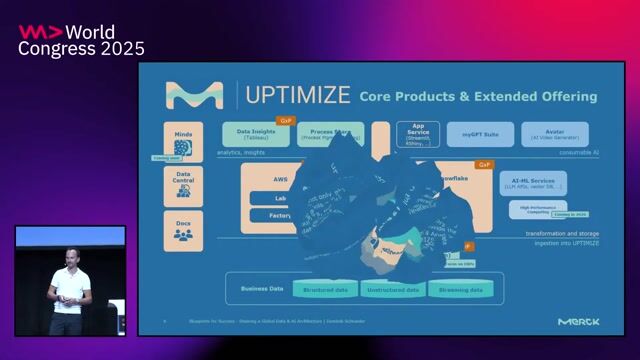
03:12 MIN
An overview of the Optimize data and AI ecosystem
Blueprints for Success: Steering a Global Data & AI Architecture
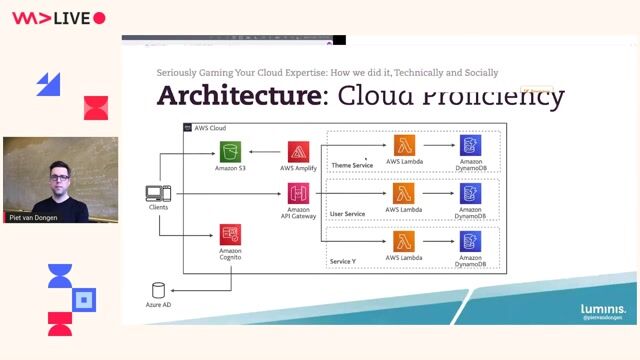
05:11 MIN
Using gamification to boost learning intensity and persistence
Seriously gaming your cloud expertise: from cloud tourist to cloud native
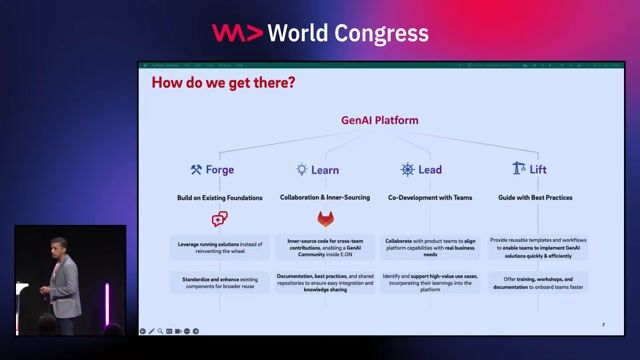
03:50 MIN
A phased approach to building the AI platform
Beyond GPT: Building Unified GenAI Platforms for the Enterprise of Tomorrow
Featured Partners
Related Videos
 25:48
25:48The Road to MLOps: How Verivox Transitioned to AWS
Elisabeth Günther
 48:54
48:54Remote Driving on Plant Grounds with State-of-the-Art Cloud Technologies
Oliver Zimmert
 39:58
39:58Leverage Cloud Computing Benefits with Serverless Multi-Cloud ML
Linda Mohamed
 29:26
29:26Empowering Thousands of Developers: Our Journey to an Internal Developer Platform
Bastian Heilemann & Bruno Margula
 22:41
22:41Empowering Retail Through Applied Machine Learning
Christoph Fassbach & Daniel Rohr
 24:22
24:22Database Magic behind 40 Million operations/s
Jürgen Pilz
 30:07
30:07Lessons Learned Building a GenAI Powered App
Mete Atamel
 30:51
30:51Why and when should we consider Stream Processing frameworks in our solutions
Soroosh Khodami
Related Articles
View all articles



From learning to earning
Jobs that call for the skills explored in this talk.


PiNCAMP GmbH
Berlin, Germany
Senior
React
GraphQL
Next.js

Media-Saturn-Holding GmbH
Ingolstadt, Germany
Intermediate
DevOps
Python
Docker
Terraform
Kubernetes
+2
Power Reply GmbH & Co. KG
Python
Terraform
AWS Lambda
Machine Learning
Continuous Integration
+1
Avanti Recruitment
Bristol, United Kingdom
£50-70K
NoSQL
Spark
Python
Redshift
+2
LinkiT
Amsterdam, Netherlands
Azure
DevOps
Python
PySpark
Terraform
+2
Europa-Park GmbH & Co Mack KG
DevOps
Grafana
Terraform
Prometheus
Kubernetes